¶ 高性能计算入门(上):软硬件结合视角
从本文开始,我们正式进入高性能计算部分。我们试图通过这两讲为大家介绍高性能计算的 Big Picture,作为高性能计算的入门,带大家周游高性能计算的各方面。
本文的主要作用是索引,对于想了解的概念,请自行搜索。
¶ 上:软硬件结合视角
计算的发展是螺旋上升的,软件和硬件的发展相互制约又相互促进,无论单讲哪个方面都不能体现高性能计算的全貌。我们试图一边介绍硬件,一边介绍软件,给大家尽可能全面展示并行计算的Big Picture。估计主要会分为这几个方面:
- 超算和并行的哲学
- 常见概念和设计:发展与现实视角
- 异构,异构,异构!
- 常用工具一览
¶ 下:并行模型:线程和进程
单个物理设备能容纳的数据是有限的,往往远远小于问题的规模。运算单元之间相互的内存可见性应该如何考虑?又应该如何交换?我们根据不同内存模型进行梳理,介绍几种常见的程序思想。
- 内存模型与程序设计
- 线程:pthread
- 线程模型上的自动并行:OpenMP Intro
- 进程间通信:MPI Intro
¶ 我们认为你掌握的一些概念
如果有不清楚的,可以 STFW(请自己搜索这个词的意思)。
- 冯诺伊曼架构
- CPU 内存 网卡等基本电子元件的作用(如果不清楚可以看刘胜与的课件:如何选择服务器硬件)
¶ 超算与并行的哲学
熟悉笔者的同学都知道,笔者聊什么都要先聊一聊哲学。超算和并行的哲学其实只有一条,就是在可以接受的时间范围内尽可能扩大问题的规模(scale up)。
这和大家平时写算法题的思路不太类似。算法题的目标是,通过算法的改进与卡常等技巧的使用,减少问题的计算复杂度,最终在台式电脑上很快计算出来。
而超算所解决的问题,通常在现有科技下难以找到更高效的解法,需要更大规模的算力。比如说地球气候模拟需要解Navier–Stokes方程,杨超老师的算法在神威·太湖之光上用一千万个核心,达到了百万倍级别的加速。就算在个人计算机上可以用优化方法达到一百倍的加速,仍然会比超算慢一万倍--这个量级足够从量变产生质变了。
这就是超算之美。用更大规模,解决更多问题,最终由量变引发质变。
听起来很简单对不对?但是方法质变的同时,遇到的问题也在质变。举两个例子:
¶ Q1
假如每台机器正常工作的概率是99%。1000 台服务器组成的集群平均多久就会有一台机器不能正常工作?
这是鲁棒性的例子。在机器数量少的时候,完全不用担心这个问题:大家的笔记本每年坏不了几次,但是在超算中心,几乎每时每刻都有机器损坏下线,每过几天程序就可能崩溃一次。但如果问题需要连续算一个月,应该怎么办?
¶ Q2
你有2048块性能相同的 CPU,计算问题的Pattern是这样的:
输入为 2048 个数字,第个数字加到第个数字上,。
假设CPU之间每个字符的通信比计算慢100倍。用一块CPU算比用2048块算要快多少?
结果是显而易见的,读到这里你可以觉得,哪个“傻子”会这样设计程序?那就看看这个Talk吧,科学家们改进了多次的图算法,没有个人电脑单线程的计算快。
这是通信的例子。通信是扩大规模中,最常碰到,也是最有意思的一个槛。软硬件厂商、科学家和工程师们如今仍在试图优化这个问题,这也是扩大规模最大的阻碍之一。
¶ 高性能计算有啥应用?
由于算法发展的相对停滞,算力增长带来的进步显得愈发重要。典型的应用比如说天气预报,气象地理模拟,计算化学,计算物理。以及前几年发展起来的计算生物学,第一性原理分子动力学等。
这两年最热的莫过于大语言模型,以及各种人工智能。训练和推理都是高性能应用。Facebook 的 OPT 175B,在 992 张 A100 上训练了一个月,对高性能的软件硬件都有非常高的要求。
以DeepMD Kit为代表的机器学习分子动力学软件在高性能计算领域也占有一席之地。2020年,随着DeepMD Kit实现的机器学习驱动的分子动力学第一性原理模拟获得了戈登贝尔奖,自然科学的高性能计算范式发生了深刻变革,越来越多自然科学采用了高性能计算方法进行研究。这种方法被命名为AI for science,目前是高性能计算的研究热点之一。
¶ 怎么实现高性能计算?
在你电脑上也能实现并行计算。几乎所有现代 CPU 都支持指令级并行,可以每周期发出多条指令,并且有很多指令可以通过单条指令操作多个数据,以提高单核性能。同时,每个 CPU 都配备了多个处理核心,可以并行处理。
不过大家写的程序通常都是串行的。每次只有一条代码在执行。高性能计算通过并行计算等算法设计,不仅把单台机器的核心用起来,而且还可以扩展到多台机器。
随着技术的发展,出现了一些专门为并行算法制造的硬件,这里带大家浅尝辄止地过一下,后面大家会学到如何驾驭这些硬件。
¶ CPU、内存和 HBM
用于高性能计算场景的 CPU, 核心数目会比个人用 CPU 更多。下图是 Intel Xeon Platinum 8480+ 的 die shot 图,可以看到一共有 56个 CPU核心。除了核心规模大,向量指令集的使用也提高了计算能力。不过这种服务器比家用级频率低,单核性能也更低。

服务器的内存和家用的也有不同。通常每个 CPU 会有 128G 到 1T 不等大小的内存。同时,服务器内存有 ECC 功能,可以避免比特翻转导致的内存错误。这里提醒下,对于数组访存应该用 size_t 或类似数据类型,int类型最大只能表示 4G 多一点大的数组,在超算环境下通常是不够的。
有一种特殊的内存叫 HBM(High Bandwidth Memory),故名思意就是带宽很高的内存。最新一代技术可以达到 2TB/s 的访存带宽,运算吞吐量很高。NVIDIA 的专业显卡、Intel Xeon Max 系列 CPU都带有这种内存,可以快速处理大量数据。感兴趣的通信可以阅读 wikipedia 有关介绍,了解 HBM 的特性。
¶ 异构加速器
CPU 是通用计算器件,可以解决逻辑复杂的问题,并且可以快速响应。但是对于某些特定问题,可以通过特化硬件的方法进行加速。
GPU 是大家最熟悉的异构加速器,基本思想是:有许多情况下计算并不复杂,但是需要计算的量特别多。对于这种场景,CPU 和 GPU 就可以比作四只牛和一万只鸡。如果任务是耕田,牛应该更能胜任,但是如果任务是吃光地里的虫子,那一万只鸡会比四头牛快很多。关于 GPU 的更多知识,可以参考cuda。
不过,还有更多其他加速器。Intel 在最新一代的 CPU 中继承了对于某些特定任务的加速器,比如矩阵乘法运算、加密解密运算等。这些运算的逻辑以电路的形式烧写在芯片上,会比通用计算快很多。FPGA 也是一种很有用的加速器,作为可编程门电路,虽然运算逻辑不是直接烧写在芯片上,但通过门模拟电路,也能达到很高的执行效率。
¶ NUMA(Non-Uniform Memory Access)
一块 CPU 的能力是有限的。比如 Intel 单 CPU “只”支持 4TB 的内存。通常我们会把两个 CPU 及其各自的外设(内存、PCIE等设备)放在同一张主板上,通过 CPU 间通信,构成一个整体。这个整体的两个部分在同一个地址空间内,可以互相访问,但是访问对方内存的延迟和带宽受限,所以叫 Non-Uniform Memory Access。
下图是浪潮 5280M6 服务器的图片。照片拍摄于 2023 年的 ASC 比赛赛场上。可以清楚地看到,有两块CPU,以及分布于CPU两侧的内存。

和 NUMA相对应的是 UMA(Uniform Memory Access),即多个 CPU 访问同一个内存池,各个 CPU 访问同一个内存模块。这样每个 CPU 访问任何内存的时间都一致。不过这种架构目前已经很少见了。
¶ 网络通信
单个节点的计算能力仍然有限,如果需要和其他节点协作,就需要进行通信。
最初,服务器通信使用的是通用的以太网通信协议,也就是 TCP/IP 协议栈。
¶ 超算集群
把各种不同分工的节点互相连接,就组成了集群。
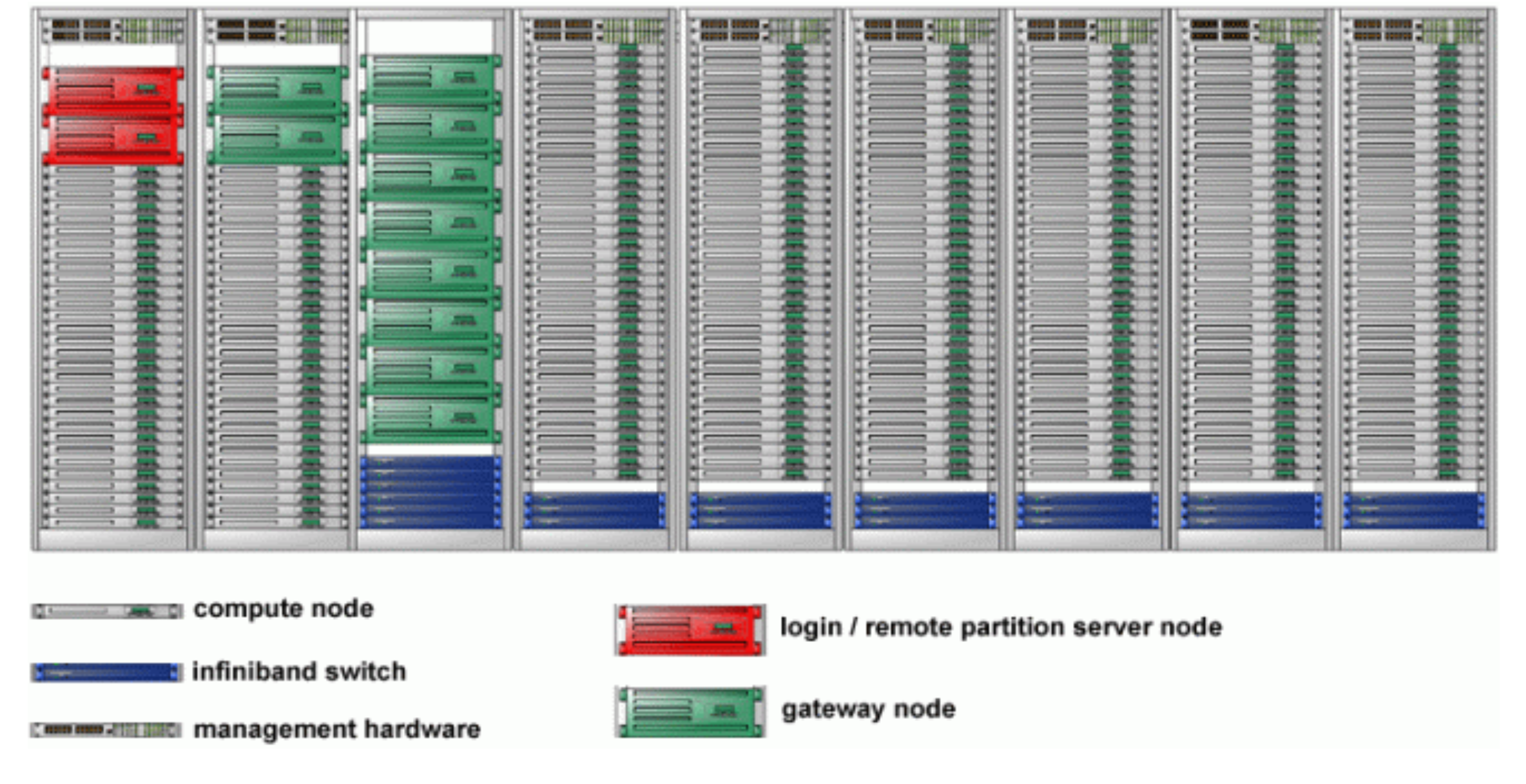
近些年,随着 CPU 的发展和 GPU 等异构加速硬件的加入,超算集群的算力也快速提高。 2017 年左右,中美两国超算的共同发展目标是建设 E 级算力的超算。但是只经过了六年时间,NVIDIA 在 23 年 5 月发布的 GH200 系列集群,随随便便就能达到 1 Exaflops 算力。